By Julien Colomb | June 1, 2018
During the second week of march, I had the chance to participate to two interesting meetings: the open science barcamp and the premierquality seminar. Both events have some online archive with results of discussion for the barcamp (https://etherpad.wikimedia.org/p/oscibar2018) and slides of the presentations for the seminar (https://www.bihealth.org/de/quest-center/projekte/premier/news/). I was stroked by the similarity in the discourses, not only concerning the problems discussed but also the solutions proposed.
Here is the first of a series of blog about the parallel between the two events and communities.
Translating quality assessment problems into open science vocabularies
The QUEST center wants to tackle the problem of the lack of reproducibility in science, a term with a large span of meanings. It goes from “reconstructability” of the analysis (ability reproduce the analysis with the same data) to the external validity (ability to reproduce the results using different conditions or species), naturally passing by discussion about statistical illiteracy and lack of rigor (ability to reproduce the same results in a different lab).
Solutions presented were to (1) assess the quality of the work during the experiment (independently of the mentoring program), i.e. make the science transparent, make it open, (2) foster collaboration having different labs testing a sub-sample, i.e. making scientific projects more open for collaboration, (3) share the data in a inter-operable (i.e FAIR) way.
Closed research process.
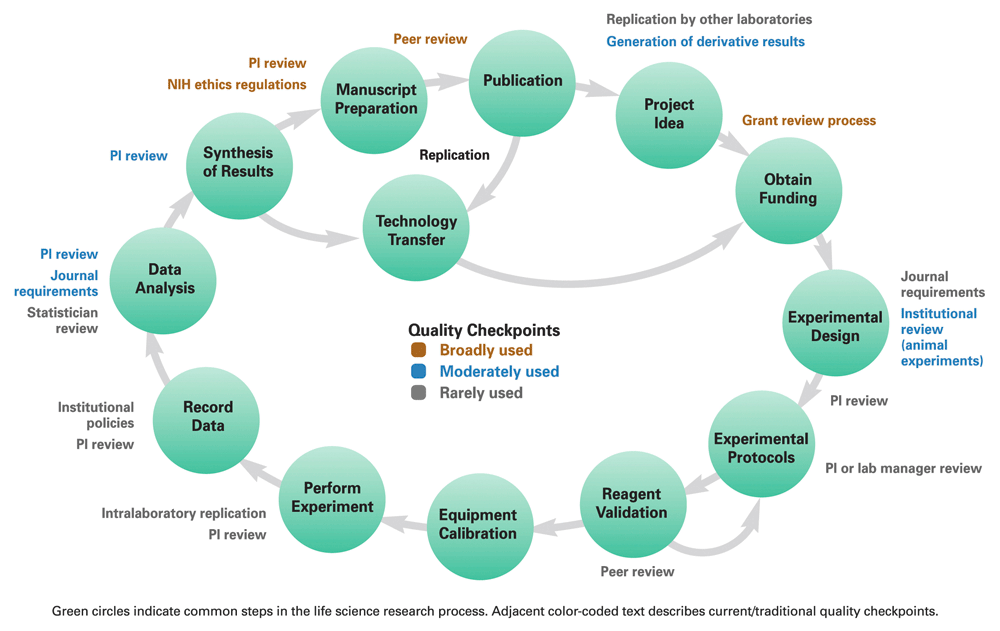 {width=80%})
{width=80%})
Rebecca Davies presented us a nice illustration of the problem (originally published at https://doi.org/10.12688/F1000RESEARCH.11334.1). While some quality control do exist in the research system (mainly article peer review and grant reviews), most of the work (i.e. the creation of data and metadata) happens with sloppy or non-existent quality control. The PI of the lab is supposed to perform this control, but we all know that they do not have time for that and that raw data are very rarely double-checked. Rebecca presented the program she is leading in the College of Veterinary Medicine, in St. Paul, Minnesota, USA. It is based on scientist’s training in quality assurance and science reproducibility. This resonates of course with the discussions about making that whole process open, as advocated by the open science community, in particular with the session 7 of the Oscibar (https://etherpad.wikimedia.org/p/oscibar2018_session7) dealing with putative career problems the report of mistakes might bring.
While both communities want to see this part of the research process to be more open, it was presented as a solution to increase accountability and reproducibility in one event, while the open science community aims farther, advocating for a data made open ASAP, in order to foster collaboration (on top of fostering research reproducibility).
From both events, it seems the time is right to take a leap forward and bring quality assessment in the lab, providing the data openly while it is gathered might be an effective way to keep good records of data and metadata. Research data management training seem to be an prerequisite for these approaches (and it has yet other benefits than promoting good quality and collaboration).
Distributed under a CC-BY license.
From Julien Colomb, http://orcid.org/0000-0002-3127-5520, data manager